

How to improve Reliability in the cloud?
Did you get a phone call from your customer saying they want to improve their application reliability while you move their workload to the cloud? If yes then continue reading this article. I will use Microsoft Azure to explain the Reliability concept and its improvement steps. You can certainly do the same in Google Cloud or Amazon AWS.
What is Reliability?
Well reliability is a derived concept. Basically you want your application to be available for your customer. Also you should ask what latency is acceptable for your application. If your application is slower or normal, your application users should not keep retrying to finish any transaction. How should your application fidelity be while your application is slow and not rendering properly. So in order to define reliability of your application you have to answer how much your application should be Available and what is your Latency that you want for your application.
Reliability = Availability + Latency
So basically reliability is something your Business has to define. You must talk to your customer and understand what kind of business they are running, what problem they want to solve, who are the target users for the application.
How to increase Reliability?
Reliability of your workload is a shared responsibility between you and your cloud provider. Platform Reliability such as datacenter, network and other hardware infrastructure is your cloud provider responsibility. However, application reliability is customer responsibility.
In order to increase application reliability you must do below:
- Choosing and Configuring correct cloud building blocks.
- Your application must be cloud aware. Like your code should have Retry logic to make sure that application is handling transient failures which is common in the cloud.
Right Building Blocks to increase Reliability
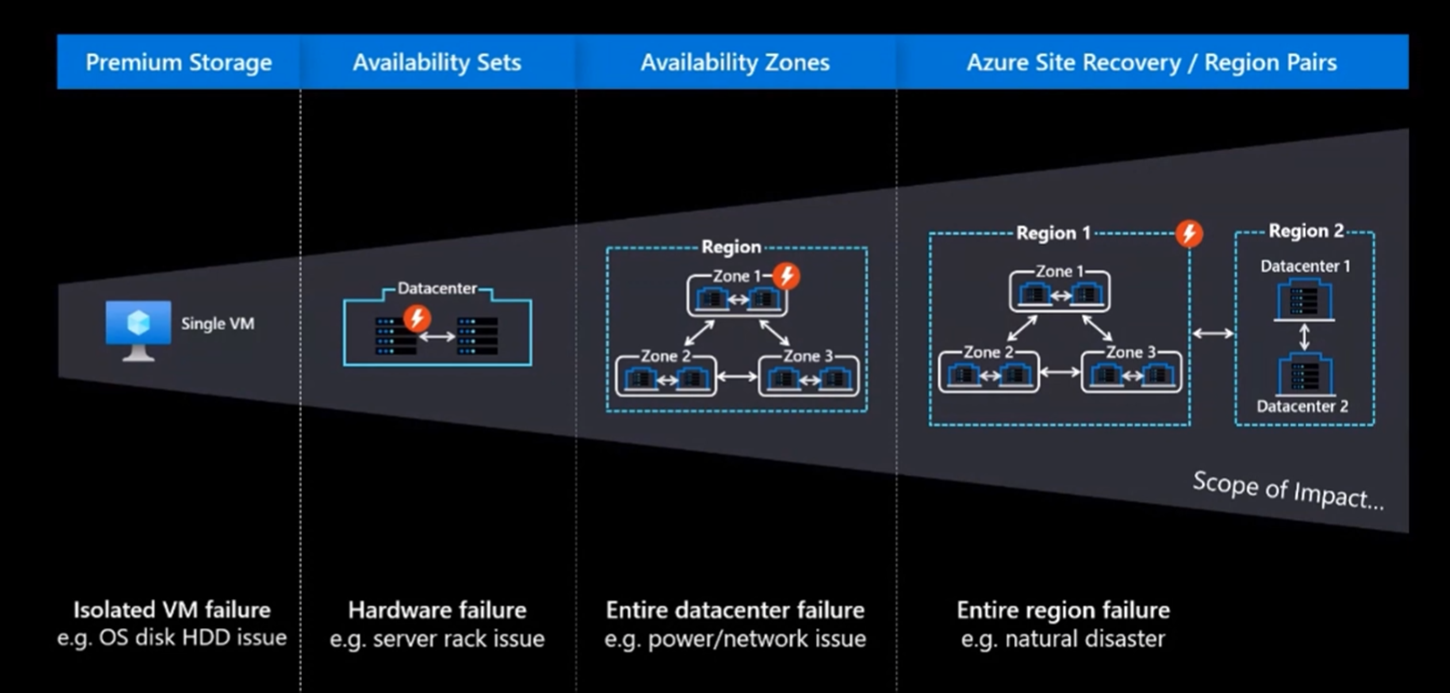
Make sure you choose the right infrastructure building blocks in the cloud to protect their reliability impacts. You have to isolate the concerns and identify them like below:
- Isolated VM failure such as OS, disk HDD(hard disk drive) issue.
- Hardware failure such as server rack issues.
- Entire datacenter failure such as power/network issues.
- Entire Region failure such as natural disasters.
In order to protect VM disk and OS issues you need to use Premium Storage from Azure Cloud. To protect from hardware failure you must create a VM inside the Availability sets. To protect from entire data center failure you must consider deploying your workload in multiple Availability Zones. Also to protect from natural disasters make sure you deploy your workload in another region as well. So in summary you have to choose correct building blocks as per your requirement to improve reliability.
How to Improve Reliability of an Existing Workload?
Start backup for your virtual machine, databases that you can enable for existing resources in Azure cloud. However, if your VMs are not in the Availability set then you can not put them in the availability set for existing resources. You have to do workaround and re-build some of them and put them in Availability sets again.
In order to improve reliability of existing workload you must follow below steps on each use case:
- Find Key components for the critical use case (which business is more concern)
- Failure Mode Analysis for the critical use case
- Calculate Composite SLA for the critical use case
- Improve Composite SLA to meet business requirement
Failure Mode Analysis Technique for Reliability
First you should talk to customers to find out which business capability they want to be up for what time. Example the purchase application written as asp.net needs to be up for 99.99 and 4 min per month down time. If business defines this then next you must learn their existing workload design consideration to achieve 99.99 SLA.
Designing for failure is the philosophy to take while designing applications in the cloud. Exploring what happens if something fails? Take the architecture, look at the portions of the application piece by piece and apply failure mode analysis. Break this down into your solution as a series of key processes. Like in your application, the customer goes and searches for an item to buy.
Step 1: Find the key components of the business use case
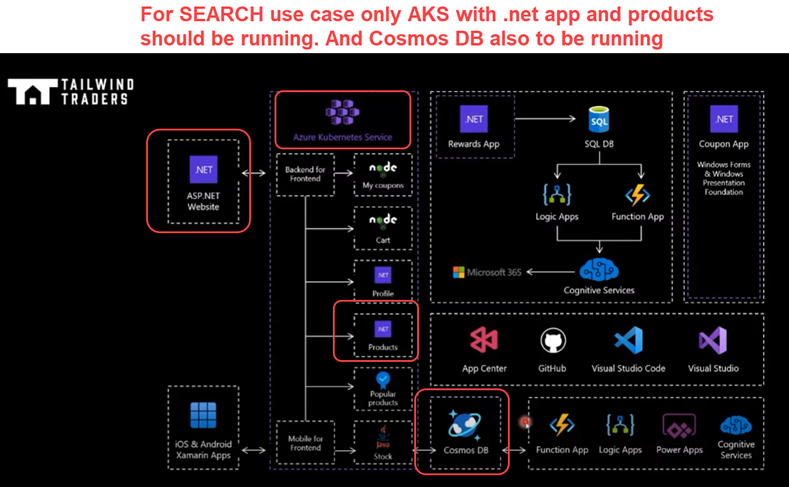
So now let’s search what component has to be working to make search possible?
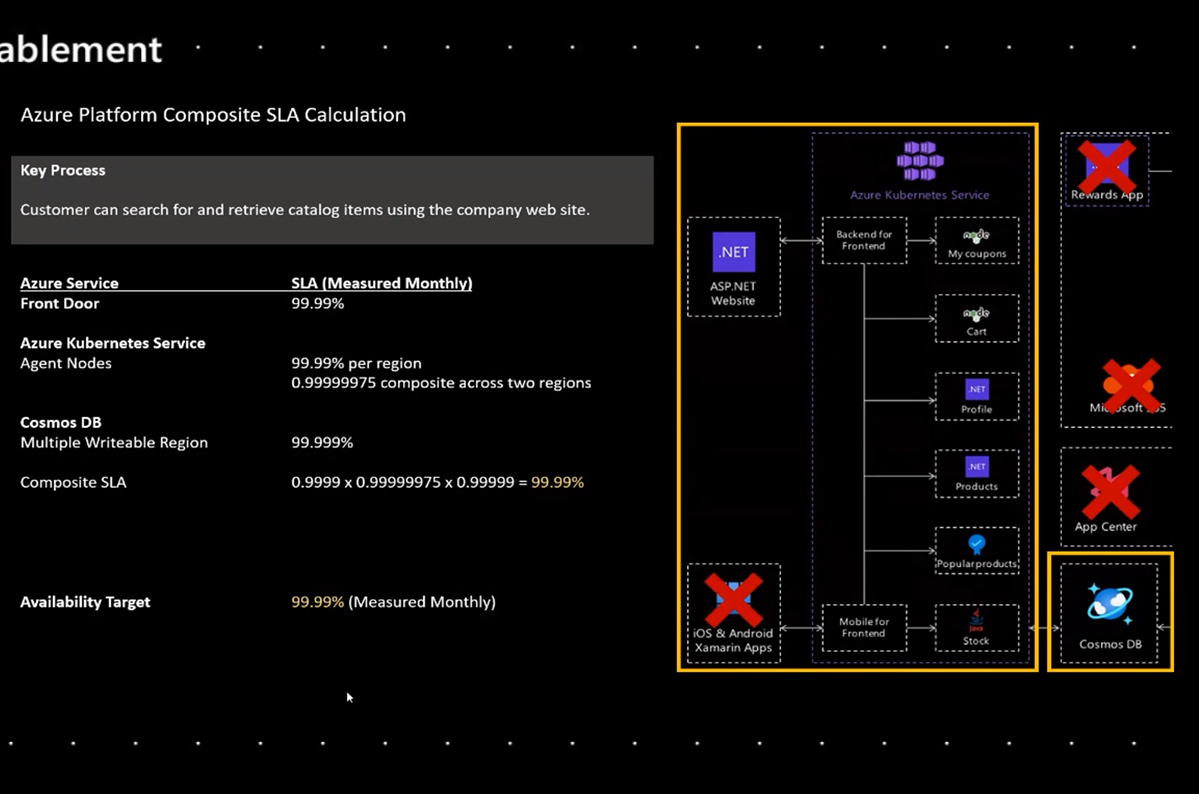
Fo below architecture example in order to make sure Search is working below components must be up and running
- AKS with .net application
- Products service
- Cosmos DB
Step 2: Failure Mode Analysis
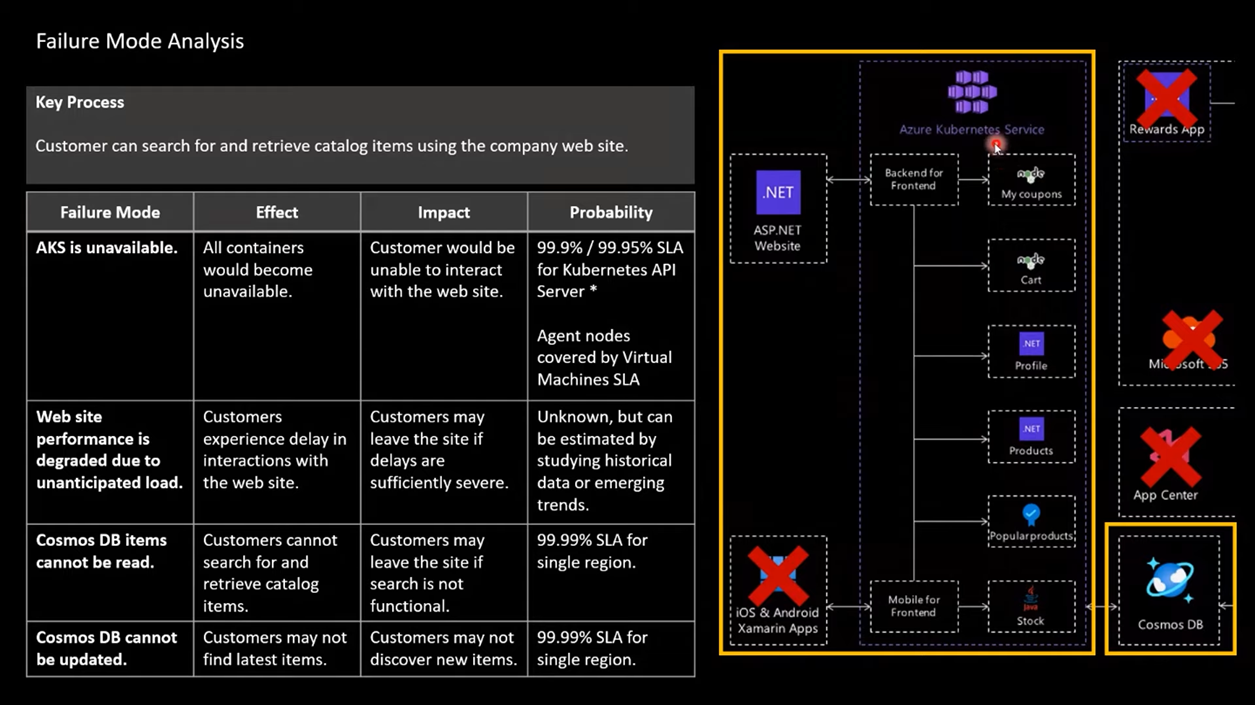
Try to write down each component failure mode and their effect, impact and chances and work with your customer to learn more. This is a collaborative effort. Solutions Architect and Customer together must do this to come up with correct decisions. For search use cases you want to check what happens if AKS is unavailable, Website is slow, CosmosDB unavailable for read and update use case.
- AKS is unavailable so we have to change the SLA to 99.95% on the API server of Kubernetes which is a controller plane. This is the SKU version we have to upgrade. In the worker plane we have a VM whose SLA is just like regular. So businesses have to think of their own requirements to opt in if they want to upgrade the SLA or kubernetes.
- Web site is down, because of fluctuation of load due to holiday session. Probability is unknown. So you must use a monitoring tool setup alert to learn more about this kind of problem. LOAD OVER TIME can be only learnt by monitoring and it’s trends.
- Cosmos DB can not read or update. Cosmos DB has 99.99% SLA for a single region. Cosmos DB can not be updated so customers can not see the latest catalog, it is also covered by 99.99% SLA out of the box by Azure cloud.
Step 3: Calculate Composite SLA
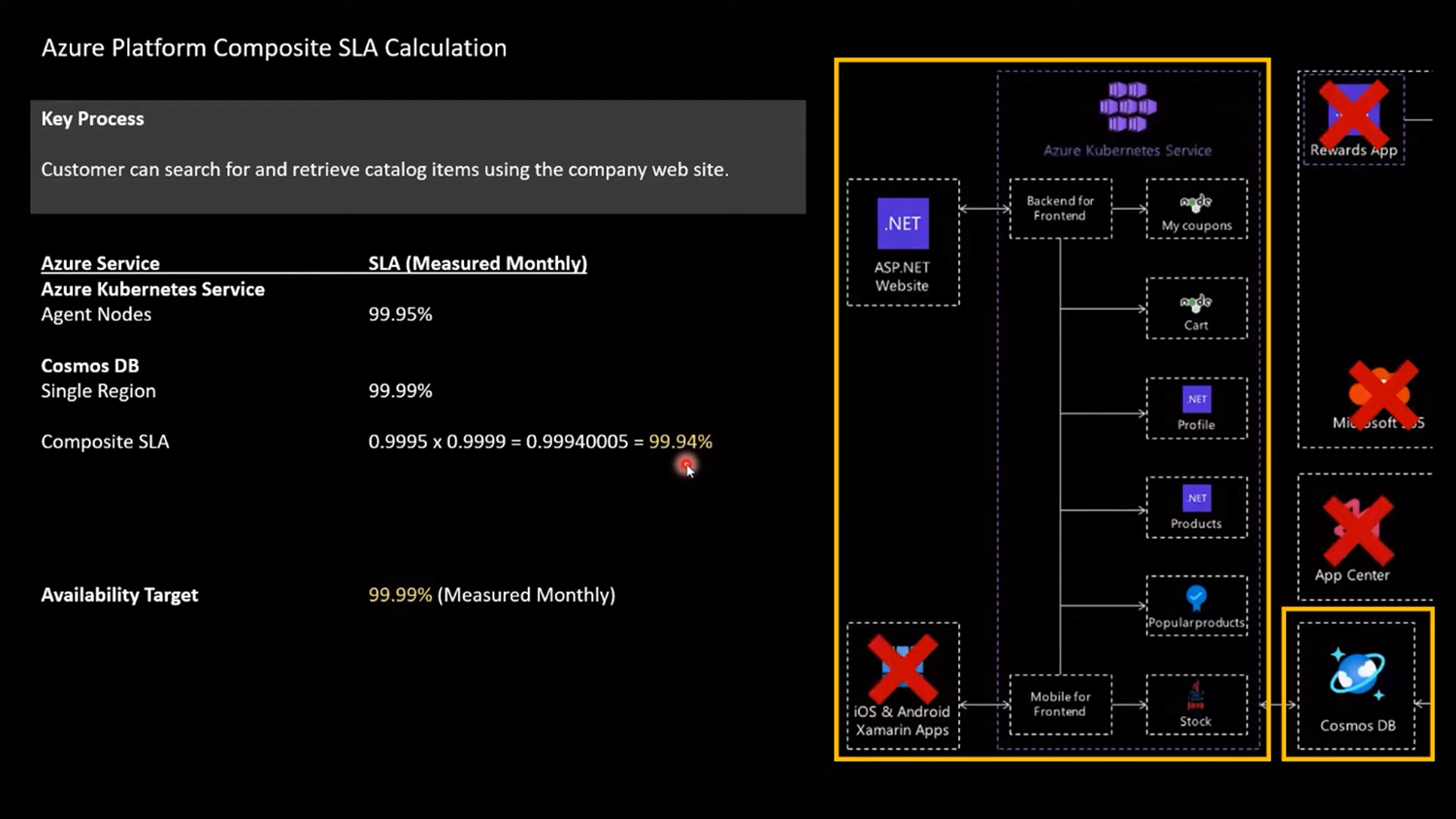
AKS SLA is 99.95% and Cosmos DB SLA is 99.99%
So overall composite SLA of AKS and Cosmos DB is 99.99 x 99.95 = 99.94%
Step 4: How to increase Composite SLA
To increase the composed availability add redundancy to the solution. Let’s make 2 AKS, if one breaks the other will work. You can put them in multiple Azure Region East/South USA. They have to be identical. Deployment of the cluster and the containers would have to be deployed in an automated way to keep them identical. IAC (Infrastructure as Code) should be in a repository and used to deploy your resources. Since AKS is in multiple regions you need DB in both regions. Cosmos DB has a multimaster database you can use in 2 regions so any change you do in one region is synchronized in both regions out of the box. You have to use Microsoft Front Door to route between multiple regions.
- AKS (Azure Kubernetes Service) with redundant will give you SLA 99.99% per region with multiple region SLA is 99.999975%
- Front Door SLA is 99.99%
- Cosmos DB with multiple writable region SLA 99.999%
Composite SLA = 0.99999975 x 0.9999 x 0.99999 = 99.99%
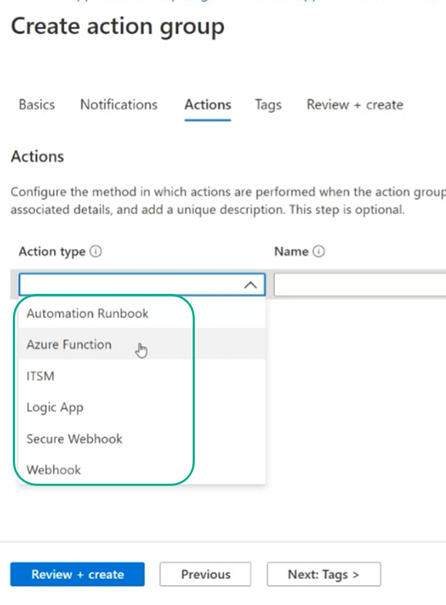
How to know if something is wrong in your web app?
Create alert rules specify conditions and for actions you can alert humans with sms, or create action groups and execute some azure functions.
Enable VM Replication for improved Reliability
In addition to backup lots of customers are focused on disaster recovery and making sure the workloads are redundant and not just backed up. Meaning that if we had a planned or unplanned type of outage. Planned means upgrades to different applications, or we are testing our disaster recovery or may be unplanned like some natural disaster or things of nature. So introduce resilience in the form of being able to access backups that are in another region and to make those come online as quickly as possible to make sure that we reduce downtime to the extent possible.
Upgrade VM to Premium Disks to increase Reliability
For production workloads, especially Big Data, SQL and other transactional DB upgrades to premium disk instead of standar disk offering. Premium disks also offer bursting capabilities.
Burst means performance on heavy load.
- On-demand bursting: you pay whenever you have burst. When you have an inconsistent workload.
- Credit-based bursting: Harvest or credit yourself with additional bursting capability when you are operating below the maximum thresholds that we have. In this case, you’re able to burn those credits by bursting when you need it without any other cost implications. So you accrue your bursting credits when you are not using them and use it when you need.
Upgrade VM to Managed Disks to increase Reliability
Un-Managed Disks where you have to set the size, throughput limit, and add more resources to scale are called unmanaged disks.
However in Managed Disk you get below processes automated for you by your cloud provider:
- Set the size, throughput limit, add more resource to scale handled by azure
- Abstract the entire management layer of storage
- Compatible with availability set and availability zones, you get 99.99% availability for production workloads.
- Resiliency : 3 replicas across multiple hardware devices
- Granular role based access control
How do I know what I don’t Know?
You have to have a long term learning process. Just wait for another disaster, unexpected event and learn. The other option is to simulate/force failures and see what happens. Say stop AKS and check if your redundancy is working. Take a more experimental model, introduce real world scenarios and see how our workload works. Game day, setup scenario, one team generating un-predictable load by un-usual way, another team observing, are we seeing alerts are coming, are we seeing redundant machine status.
Summary
In order to get Reliability increased for your customers workload you must speak with them and understand their critical use case which they care most about. Follow the steps that I suggested in this article to come up with the desired reliability state defined by business by doing failure mode analysis in depth one by one for each important use case. You may have to teach your customer about premium disks for VM and their SLA improvement because of upgrading to premium disk. What is managed and unmanaged disks after migrating to managed disk resilience can be increased since it automatically replicates the disk into 3 multiple hardware devices. Consider replicating virtual machines to protect them from regional outages. Setup Azure Virtual Machine backup for improved reliability and to protect from human error or DB corruptions. Also make sure you set up alerts for your applications to send you email or create zendesk tickets whenever it is down. I hope now you have a good understanding about reliability improvement.
Thanks for reading my article till end. I hope you learned something special today. If you enjoyed this article then please share to your friends and if you have suggestions or thoughts to share with me then please write in the comment box.
Rupesh Tiwari
Founder of Fullstack Master
Email: rupesh.tiwari.info@gmail.com
Website: RupeshTiwari.com



